[ Pandas ] Pandas Data frame 생성 및 다루기
- Pandas
Pandas는 DB 등의 레코드 데이터를 다루는데 특화된 라이브러리입니다.
머신러닝에서 다루는 다양한 리얼 데이터들은 주로 DB나 CSV 파일 등 레코드 구조를 가지고 있기 때문에 먼저 Pandas로 읽어 들인 후 이를 다시 처리에 특화된 numpy로 변환하는 경우가 많습니다.
아래의 구문으로 pandas를 사용합니다.
import pandas as pd - Pandas 기초
numpy 가 numpy array 를 기본 자료구조로 처리한다고 할 때,
pandas는 data frame이라는 자료형을 기본으로 다룹니다.
- Data frame 수동 생성
대부분 csv와 xlsx 파일을 읽어 들이는 경우 자주 사용됩니다.
하지만 이번 글에서는 간단히 만들어 여러 테스트를 해보겠습니다.
아래와 같은 데이터가 존재할 때 여러 방법으로 테스트 가능합니다.
df = pd.DataFrame( {
'A' : [1,2,3],
'B' : [4,5,6]
})
df
똑같은 구조를 다음과 같은 방식으로 만들 수도 있습니다.
df = pd.DataFrame([[1,4], [2,5], [3,6]], columns = ['A','B'])
df
레코드 구조를 다루는 자료답게 index를 생성할 수도 있습니다.
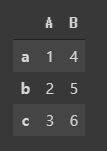
데이터 프레임의 index , column 은 다음과 같이 확인이 가능합니다.

- series
하나의 칼럼 값들을 1차원 배열 형태로 추출하는 것을 series라고 합니다.
print( df['A'] )
print( df.A )
다음과 같이 추가할 수도 있습니다.
df['C'] = [0.1,0.2, 0.3]
df
다음과 같이 삭제할 수도 있습니다.
del df['C']
df
- Data frame과 numpy 배열
pandas는 내부적으로 값을 저장할 때 numpy 배열 형태로 저장합니다.
그래서 다음과 같이 간단하게 numpy 배열을 추출할 수 있습니다.
arr = df.values
print(arr)
print(arr * 2)
특정 칼럼 ( series )만 추출하고 싶다면 다음과 같이 추출할 수 있습니다.
df['A'].values
- 구구단 테이블
numpy의 np.arrange를 사용하여 아래와 같이 구구단 테이블도 출력 가능합니다.
import numpy as np # np.arange 사용
df= pd.DataFrame()
for i in range(2,10):
s = str(i) + "단"
arr= np.arange(1,10)
df[s] = arr * i
df